

Joint demo delivered 40% faster time-to-insights and 40% lower CPU utilization
Astera Labs, alongside its ecosystem partners, Supermicro and MemVerge, has won the Future of Memory and Storage (FMS) 2024 Most Innovative Technology Award. At FMS 2024, we jointly demonstrated how AI inferencing can gain significant benefits using CXL®-attached memory.
Astera Labs is a second time winner, having previously won the Most Innovative Enterprise Business Application award for a high-performance OLTP (Online Transaction Processing) with CXL-attached memory demo at FMS 2023, also in collaboration with Supermicro and MemVerge.
Users of Generative AI tools such as AWS CodeWhisperer, Microsoft Co-Pilot, Google Colab, and Replit have come to expect real-time responses from AI Assistants – but on-demand insights and accurate responses require a huge amount of processing and memory behind the scenes. Let’s dive in
LLM Memory Demands Continue to Increase for AI Servers
Large Language Models continue to grow exponentially and push AI servers to provide larger memory footprints for AI inferencing applications. For example, Meta recently released Llama 3.1 requiring 810GB of memory in its original FP16 precision version of the 405B model1. Llama 3.1 requires an additional 243GB as processing overhead for a total requirement of 1053GB.
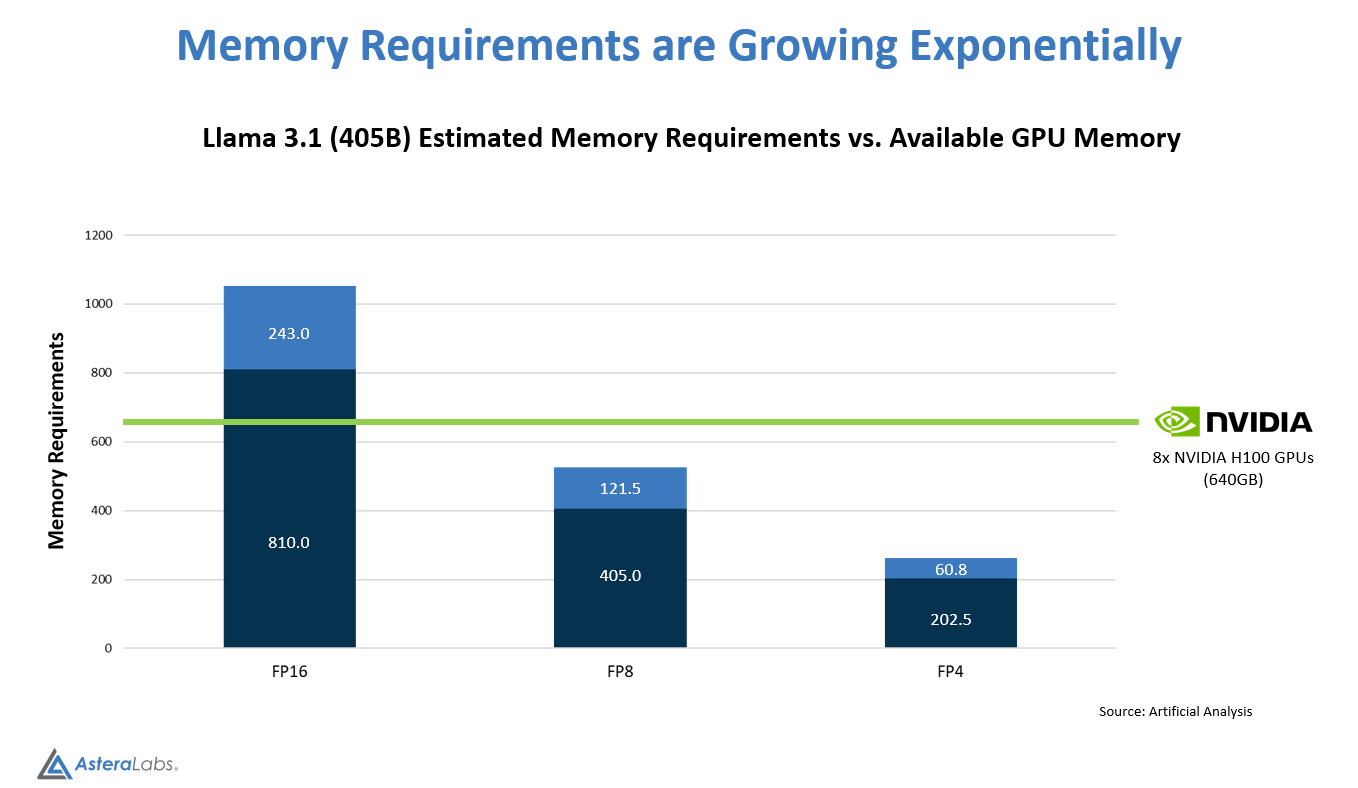
Figure 1: Llama 3.1 Requires 810GB of Memor
To put this growth into perspective, loading the previous generation Llama 2 with fewer parameters only required 140GB of memory (see Figure 2).

Figure 2: Llama 3.1 (405B) vs Llama 2 (70B) Memory Footprint Comparison
Providing real-time insights with these LLMs can quickly generate multiple terabytes of data that exceeds the memory footprint of the AI server and requires caching on SSDs. This lower performance cache tier results in reduced GPU utilization and slower token generation for data centers that have invested heavily in these expensive build outs, creating a performance dead-end that is non-ideal for growing demands from applications.
Optimizing AI Inferencing Performance and Increasing ROI with CXL-Attached Memory
To overcome this memory footprint challenge, our joint demo at FMS proposed a way to easily expand memory capacity and bandwidth using CXL-attached memory for AI Inferencing systems.
The award-winning demo featured a Supermicro 4U GPU server, two NVIDIA L40S GPUs, and two Aurora A1000 cards, powered by our Leo CXL Smart Memory Controllers, with MemVerge’s benchmark test tool, based on FlexGen2, as the LLM software engine.
With our high-performance, reliable, and secure Leo CXL controllers, we were able to:
- Accelerate token generation with 40% faster time-to-insights for users
- Lower CPU utilization by 40% per query, allowing the ability to increase the number of LLM instances per serve
- Increase LLM instances by 2x per server to help maximize the ROI of deploying expensive GPU resources
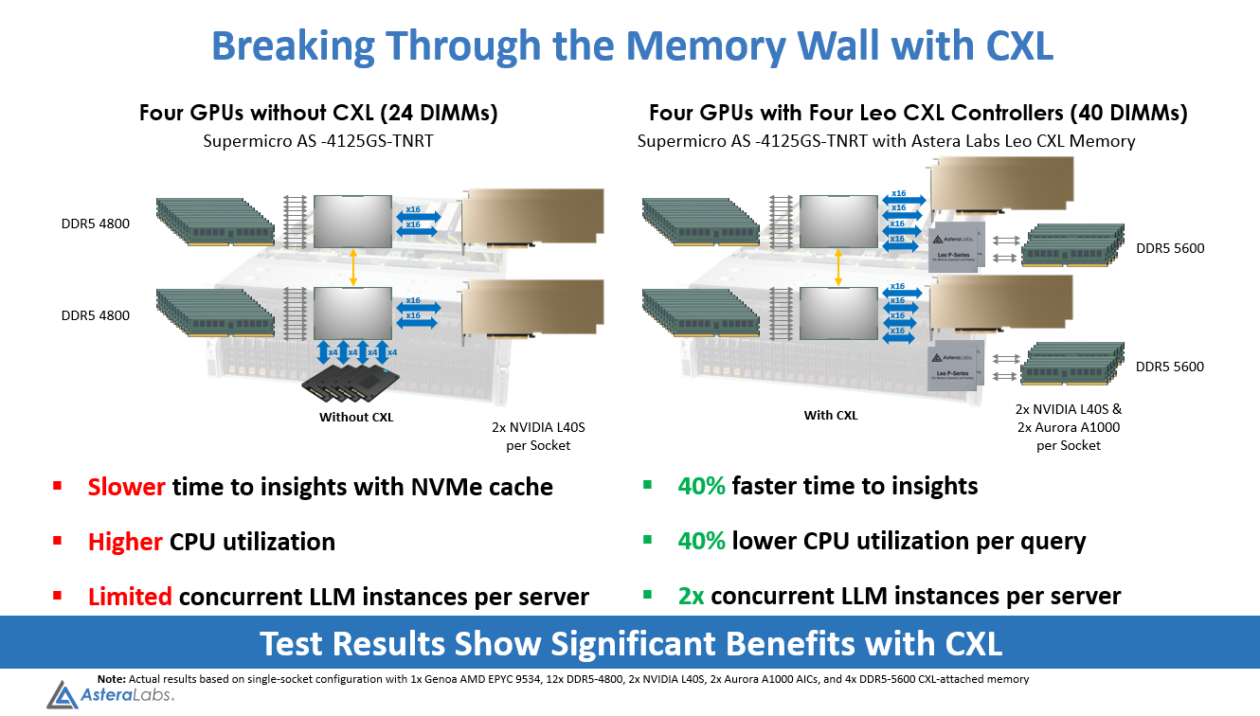
Figure 3: AI Inferencing System Setup & Results
AI inferencing is used in a wide variety of industries from natural language processing to medical diagnosis to content recommendation. By accelerating time to insights for AI inferencing, Astera Labs, Supermicro, and MemVerge are removing memory bottlenecks in AI infrastructure and unleashing the full potential of these applications.
Check out the video demo and learn more about our Leo CXL Smart Memory Controllers
References
- Philipp Schmid, et al., “Llama 3.1 – 405B, 70B & 8B with multilinguality and long context.” Hugging Face (blog), July 23, 2024, https://huggingface.co/blog/llama31
- Ying Sheng, et al., “FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU.” arXiv (white paper), June 12, 2023, https://arxiv.org/pdf/2303.06865
About Astera Labs
Astera Labs is a global leader in purpose-built connectivity solutions that unlock the full potential of AI and cloud infrastructure. Our Intelligent Connectivity Platform integrates PCIe®, CXL®, and Ethernet semiconductor-based solutions and the COSMOS software suite of system management and optimization tools to deliver a software-defined architecture that is both scalable and customizable. Inspired by trusted relationships with hyperscalers and the data center ecosystem, we are an innovation leader delivering products that are flexible and interoperable. Discover how we are transforming modern data-driven applications at www.asteralabs.com.
CONTACT: Joe Balich